Finally, demand modeling offers one unified model of real world behaviour. Instead of looking at demand as a sequence of independent processes separated by multiple inventory levels, it views it as a single demand signal spanning the entire supply chain. This demand signal contains highly detailed stochastic information preserving full variability and volatility detail, not just about the demand quantities, but also the order-line frequencies and quantities per order-line. This approach also minimizes the bullwhip effect.
← BLOG
Why SAP APO Can’t Forecast Demand in Complex Environments
Manoranjith Pathekkara, managing director at LogicaMatrix (www.logicamatrix.com), writes on the inherent limitations of SAP APO that prevent it from accurately forecasting in complex supply chain environments.
What’s changed?
Most of today’s supply chains are far more complex than when planning systems like SAP APO were created in the 1990s. Through the years business complexity has grown, fueled by multi-channel marketing, demand shaping, and the impact of the Internet on buying. There are more products, shorter life spans, and an explosion of product proliferation—adding complexity to the supply chain and increasing demand volatility. SAP APO is not equipped to address today’s supply chain challenges and that makes demand forecasting and supply chain planning more cumbersome and off target with APO or similar tools.
APO’s“Top-Down” Demand Forecasting
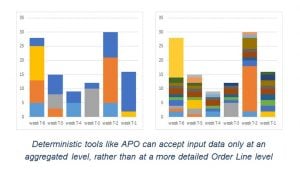
Despite the added complexities in today’s supply chains, SAP APO still applies the traditional “top-down” approach to forecasting based on aggregated data. This approach aggregates demand to smooth out variability, which makes it easier to generate a high level forecast, but the Item-Location level forecast quality is poor because demand signal details are dismissed along with the ‘noise’. So this approach of aggregated planning and then applying slicing and dicing rules only works for simple and highly predictable businesses with a few fast-moving commodity items and a single channel distribution.
Typically APO aggregates along the three dimensions; product structure (hierarchy), distribution hierarchy and/or on timescale before generating the forecast. Then it disaggregates using a “splitting” function. When these high-level forecasts are split into an Item-Location level (the level at which business decisions are taken) of detail for inventory and replenishment planning, crucial granular information about volatility and error is lost. For example, splitting monthly data into weeks can increase forecast error by more than 40 percent. Similarly splitting National/SKU aggregates are split into Ship-From detail can also increase forecast error by about 40 percent.
In addition, such slicing/dicing operational rules may be framed based on planner’s experience, thumb-rules or even by the APO system itself that may have been developed long back or adjusted occasionally. This adds latency into the forecast as actual market trends such as product mix or regional/zonal trends deviate from the norm.
Another challenge for APO is planning run time. When APO plans at a more detailed level of hierarchy – product, channel and/or time scale – the result is much longer run times than most businesses can accommodate. This is because the forecast in APO is developed using multiple time series methods. Then the one with the least error is picked and finalized by the system. This is quite inefficient and time consuming as the planning for each item is repeated many times. This is further aggravated if limits are also defined for forecast error. As the required planning granularity increases, APO’s algorithms will go bust if it can’t model demand at that level of detail and it ends up giving erratic results or eternal running times.
Finally, ‘noise’ is not forecastable. Many times when planners manually adjust the forecast, they are trying to predict the noise that the forecast could not. This is because forecasting and demand planning systems like APO are deterministic; their internal processes view all data as exact. They take exact values as input, and they output exact values. The forecasting calculation is unaware of the uncertain nature of the demand.
That’s why, with this forecasting, it’s impossible to cleanly separate ‘signal’ from ‘noise’. Any deviation in demand, however normal, is considered as error, since the forecast is an exact number. Any noise also shows up as variability and is accounted for in exactly the same way as the variability in the signal.
Demand Modeling – A Different Approach
A different approach is demand modeling. Being stochastic, demand modeling doesn’t calculate just one number forecast, but calculates a range of numbers (confidence interval), each with a probability to occur and adopts the number with the highest probability as the forecast. The probability distribution is not assumed to be normal; instead a combinatorial model is adopted.
Demand modeling works differently. It separates the signal and the noise. Signal is data that has predictive value. Noise does not. So when you model demand, you don’t try to guesstimate the noise. It’s futile to attempt to predict noise, so why waste the time, effort, and cost? Instead, demand modeling improves the forecast by getting progressively better at isolating the signal from the noise.
Demand modeling considers the range of values and their probabilities. The signal is not an exact number, but a range of values each with a probability of occurring—just like overall demand in the real world. There is variability, but the variability is part of the signal. The difference between signal and noise is the portion of demand that is predictable and the portion that is not.
Traditional forecasting ignores the inherent stochastic nature of demand. Demand modeling embraces it.
Because the signal is determined by “decomposing” the data into a signal and a noise portion, demand modeling makes the granularity of the baseline demand as detailed as possible. The more detail, the more signal is preserved—and the clearer the signal can be identified from within the noise. The most commonly used granularity is individual sales order-line, daily by item and by ship-to location.
From this detail, all kinds of patterns can be identified. For example, each ship-to location may show clear ordering patterns favoring certain days of the week, and may exclude other days completely, like Saturdays, Sundays, and holidays. Similarly, there may be obvious patterns for weeks within the month, driven by sales targets in fiscal calendars. This detail allows the signal to be automatically detected.
Additional information—seasonality, promotions, market intelligence—further fine-tunes the separation of signal from noise for a “quieter,” more accurate forecast. As additional information is provided, the signal is increasingly isolated from the noise.
Understanding Demand Volatility
Forecasting today requires understanding the demand signal at the Item-Location level in order to see customers trending up and down, regions growing or shrinking, and SKUs exhibiting unusual behaviour. The most important information about this demand volatility is at this granular detail.
Demand modeling goes beyond the standard time-series forecast to build an order-line-based baseline forecast from the bottom up (SKU-Location level). It then automatically adjusts the baseline by “sensing” stimuli and demand indicators at a detailed Channel-Item-Location level. It can also employ the power of machine learning to anticipate end-consumer market demand, modeling demand shifts from trade promotions, new product introductions, extreme seasonality, and product cannibalization. It also handles fragmented intermittent demand, new products and seasonal changeovers.

For a report on this topic, click on the link below:






